Is your architecture RESTFul?
An architecture could be REST Like or RESTish
To be RESTFull an architecture should follow 6 rules, known as RESTFul Architectures Contraints:
- Client – Server architectural principle
- Uniform interface, that is the use of well-defined communication contract between the client and the server
- Statelessness, the server must not manage the state of the application
- Caching, the server controls the caching of response using HTTP header for caching
- Layered system, multiple layer managed independently
- Code on demand (optional), it means that the server could send to client also some code that could be executed by the client
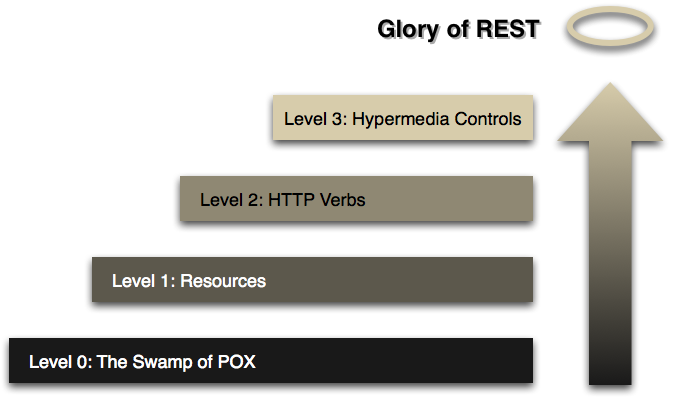
Based on the rules above, an architecture could have 4 levels/score, from 0 to 3 (Richardson Maturity level)
Client – Server
It’s basically about the separation of the concerns (SoC).
It’s an architectural principle used in programming to separate an application into units, with minimal overlapping between the functions of each individual unit.
So Client and Server are not sharing any code and they are not executed in the same process.
Server doesn’t call directly the Client, and viceversa. They are decoupled. There is no dependency between them.
Client and Server can change without impacting each other.
Uniform Interface
Client and server shares a common technical interface.
An interface is a technical contract for communication between client and server, that’s nothing about business constraint.
the contract is defined by HTTP method and media types.
The advantage is that it decouples totally client and server. They are 100% technologically independent to each other.
the 4 guiding principles
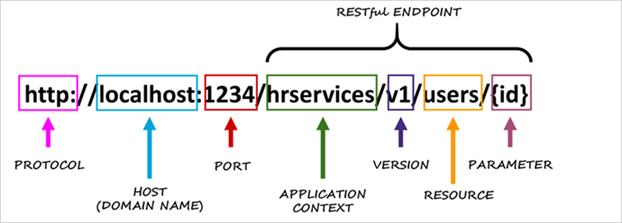
- identity of the resource (uri/url), the client can call a url to manipulate the resource
- representation of the resource, the data can be represented differently and in a different format from how it is managed on the server side
- self-descriptive messages, request and response have enough data to process request and response.
- Server can use content-type, http status code, host (which host is the response coming from)
- Client can use Accept.
- Hypermedia, it means that the server send back to client not only the data but also the action that the client should execute (known as HATEOAS)
Statelessness
Each client request is indipendent
Server receives all info it needs from the client request
Caching
A typical web application can have multiple level of caching.
Local cache, the one managed by the browser.
Shared cache on the gateway and on the application server
The advantages can be performance ones and scalability
Response messages should be explicitly marked as cacheable or non cacheable .
Caching is managed by the server thanks to the http headers.
cache-control header
cache policy directive: who, how long, under what condition. Ex:
cache-control: private;max-age=120
it means that only the client can ask for caching and that the cache will be stored only foe 120 seconds
expire header
This header specifies a fixed date/time for the expiration of a cached resource. For example,
Expires: Sat, 13 May 2017 07:00:00 GMT
means that the cached resource expires on May 13, 2017 at 7:00 am GMT
ETag
A response header that identifies the version of served content according to a token – a string of characters in quotes, e.g.,
"675af34563dc-tr34" – that changes after a resource is modified. If a token is unchanged before a request is made, the browser continues to use its local version.
Layered System
Client-server architecture consists of multiple layer. It’a a one way path: a layer can’t comunicate with the previous layer.
layers can be moved, added, deleted based on needs