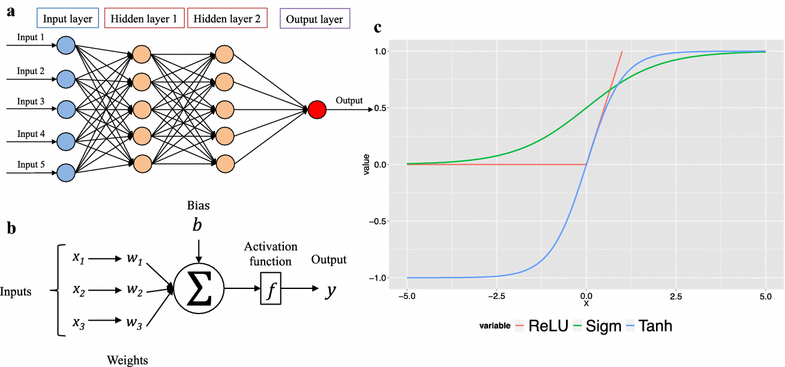
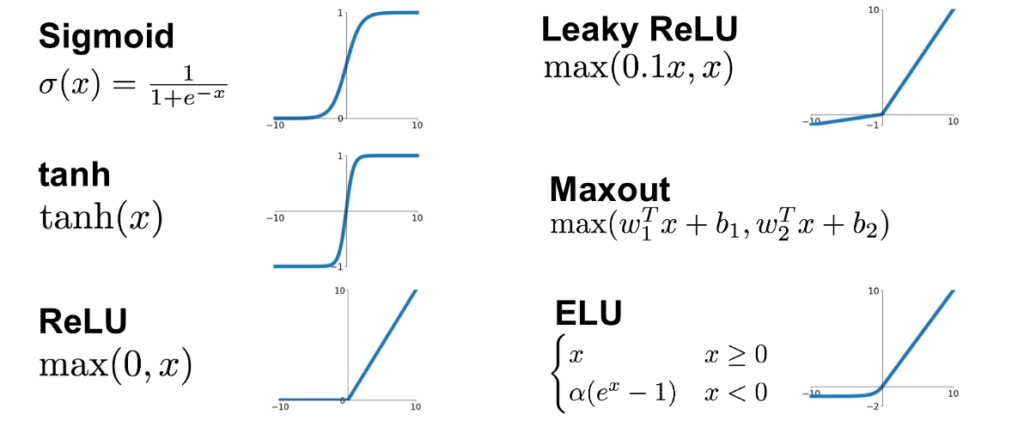
Unlocking the Power of Neural Networks: A Deeper Look
Today, we’re diving deeper into the fascinating world of neural networks, shedding light on some critical concepts.
Label and Features:
- Label (output): Labels are the ultimate goals for our neural networks. They’re like the answers to a challenging question. When you show your AI a picture of a cat, the label would be “cat.” It’s what the network aims to predict.
- Features (input): Think of features as the building blocks of your data. They’re like the clues that help the network understand and make predictions. In an image, features could be the whiskers, fur, and pointy ears that scream “cat.”
Example with Label (Used for Training):
When we train a neural network, we provide real data with both features (like the cat’s fur and whiskers) and labels (the “cat” tag). The network uses these paired examples to learn how to make predictions accurately. It’s like studying with answer keys to get better at a quiz.
Example without Label (Used for Testing):
For testing, we give our network real data (with features) but keep the labels hidden. The network makes predictions, and we see how well it does. This helps us evaluate its ability to work with new, unlabeled data.
Model:
The model is the brain behind the operation. It’s a mathematical representation of how the network should process data to produce the correct output (label). The model learns by tweaking its internal parameters, often referred to as “weights and biases.”
Regression vs. Classification:
In the world of machine learning, we have two main types of tasks: regression and classification.
- Regression: This is like predicting a number, such as the price of a house given its size. The model finds a function to map inputs (features) to a continuous range of values.
- Classification: Here, we’re assigning labels to data. It’s like deciding whether a given image is of a cat or a dog. The model sorts data into predefined categories.
Training and Loss:
Training is the phase where our neural network learns from examples. It fine-tunes its model to make better predictions. Loss measures how far off the network’s predictions are from the real labels. It’s like a report card telling the network what it needs to improve.
Linear Regression:
Linear regression is a fundamental technique in machine learning. It’s like drawing a straight line through data points to find the best fit. The goal is to minimize the squared loss, which measures how far each prediction is from the actual label.
The famous formula is
y = mx + b
where y is the label (output), m (or sometimes w) is the wheight, x is the feature (input) and b is the bias
The linear regression model uses a loss function called squared loss (RSS), which quantifies the error between observations and predictions. This loss guides the model in adjusting its parameters (m and b) to get closer to the real labels. In essence, it helps the model become a pro at drawing those best-fit lines. Formula for squared loss is
sum of all (label - prediction(x))2 ==> sum(y - (mx+b))2The “adjusting” is an iterative phase. At each loop the model tries to reduce the loss applying a new value for m. The new weight value is of the weight plus (or minus, it depends if the loss is negative or positive) a value that will allow us to reach the 0 loss in an efficient way, that is in less iteration than possible. This iteration represents basically the learning rate.
Understanding these concepts is like unlocking the secret language of neural networks. They’re the tools and principles that underpin AI’s incredible capabilities. Stay curious and keep exploring this exciting world!